
CQRS – a new architecture precept based on segregation of commands and queries
by Marco Heimeshoff, Philip Jander
CQRS is a successful alternative to the traditional multi-layer model for systems with parallel user access. This precept requires a division into behaviour and read models, enabling the business logic, the key component of an application, to be developed decoupled from data provisioning for user interfaces and reporting.
Apart we are strong
CQRS (Command Query Responsibility Segregation) is an architectural precept, the core feature of which is a division of the software architecture into two parts [1, 2, 3, 4] with clearly separated responsibilities – execution of commands which result in changes to the state of the software system, and side-effect free processing of queries. This separation is an extension of Bertrand Meyer's CQS (command query separation) principle [5, 6], which calls for an analogous separation for an interface's individual methods.
CQRS is far from being a new concept. It should rather be viewed as a contemporary response to the omnipresent vertical multi-layer model used by typical n-tier applications. The standard arrangement of database (relational), data access layer (O/R mapper), business logic, application layer and presentation layer usually entails violating the single responsibility principle (SRP) [7] at the software architecture level. The data access and business logic layers are used both to validate and execute user actions and to provision data for display by the presentation layer and reporting. Developers and architects often unthinkingly buy into this intermingling of two different responsibilities – with fatal results. The result is that implementation of process logic requirements is compromised by the need for reasonable query processing performance. On the flip side, implemented behaviours also impede the rapid return of large data volumes in response to queries.
CRUD
CRUD stands for create, read, update and delete, i.e. exclusively basic database operations, without any functionality from the actual application domain.
Should a system constructed using this model need to be used by several users simultaneously, it quickly hits performance limits and is difficult to improve. With increasing complexity comes declining maintainability. Attempts to counter this often result in desired behaviour in the business logic layer being neglected, with excessive emphasis on data and structures. In the extreme case, you end up with spreadsheet or CRUD (see box) applications, in which mapped processes and business rules are pushed out of the software and into operating manuals. Closely related is the "anaemic domain model", an anti-pattern which involves excising behaviour from the object-oriented model and reducing it merely to fields and validation.
CQRS resolves this conflict by introducing two models, one for mapping business logic (frequently in the shape of an object-oriented domain model) and one for provisioning data (read model). This division not only permits both models to be optimised for their individual responsibilities, it also makes testing business logic significantly simpler and paves the way for a whole range of simplifications. This can mean doing without a number of key technologies – O/R mappers, database clusters and caches are all rendered superfluous, and it is even possible to do away with using relational databases.
A prototype architecture
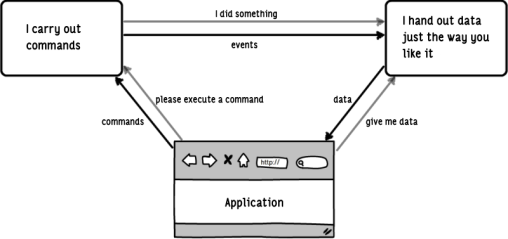
![]() Figure 1: Control and data flow in a CQRS architecture. The application sends commands to the business logic model. It publishes events as the result. The read model evaluates the events and uses them to produce data for querying by the application.
Figure 1: Control and data flow in a CQRS architecture. The application sends commands to the business logic model. It publishes events as the result. The read model evaluates the events and uses them to produce data for querying by the application.
CQRS describes an architecture with segregated paths and responsibilities with which, on one side, behaviour for modifying the system state is executed and, on the other, data can be queried (fig. 1). Different design precepts provide plenty of design latitude for selecting a specific implementation of this principle. Although this latitude may be confusing at first, it is helpful and important for optimising the general direction of system architecture design for non-functional requirements. This article restricts itself to presenting one common variant. The authors combine CQRS with the event sourcing persistence mechanism [8] and an object-oriented domain model, e.g. domain driven design (DDD) [9, 10, 11], for the business logic. An overview of the information flow within the architecture is given in figure 2.
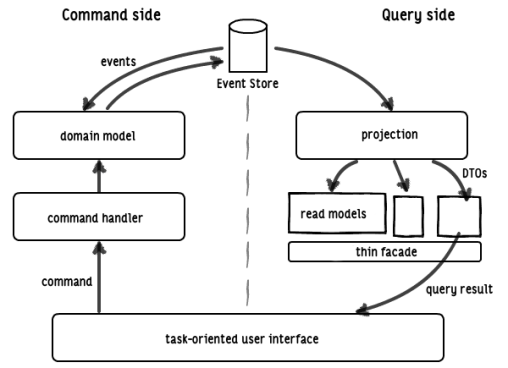
![]() Figure 2:A specific CQRS architecture. Primary data storage is in the event store. Depending on requirements, read models can be provisioned in various different forms.
Figure 2:A specific CQRS architecture. Primary data storage is in the event store. Depending on requirements, read models can be provisioned in various different forms.
The individual components are introduced next.








![Kernel Log: Coming in 3.10 (Part 3) [--] Infrastructure](/imgs/43/1/0/4/2/6/7/2/comingin310_4_kicker-4977194bfb0de0d7.png)

![Kernel Log: Coming in 3.10 (Part 3) [--] Infrastructure](/imgs/43/1/0/4/2/3/2/3/comingin310_3_kicker-151cd7b9e9660f05.png)








