Google's reCAPTCHA dented
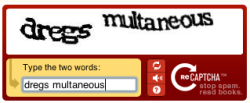
A reCaptcha in action
Google has denied that the current version of its reCAPTCHA captcha service contains vulnerabilities which make it easier for spammers to guess displayed words using automated scripts. Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA) is intended to render tools used by spammers and other criminal elements to automate activities such as creating forum and email accounts, ineffective. To do so, techniques such as requiring a user to enter graphically distorted text to confirm registration are used.
At the weekend, software developer Jonathan Wilkins published a document![]() describing a procedure which can be used to increase the hit rate for automatic recognition of Google captchas to nearly 18 per cent. This would make the reCAPTCHA procedure as good as cracked, since it would allow botnets, for example, to create large numbers of email accounts with reputable providers and use them to send spam. Wilkin's procedure does, however, relate to the reCAPTCHAs which were in use in early 2008.
describing a procedure which can be used to increase the hit rate for automatic recognition of Google captchas to nearly 18 per cent. This would make the reCAPTCHA procedure as good as cracked, since it would allow botnets, for example, to create large numbers of email accounts with reputable providers and use them to send spam. Wilkin's procedure does, however, relate to the reCAPTCHAs which were in use in early 2008.
Wilkins has admitted to The H's associates at heise Security that Google revamped its reCAPTCHA system at the end of last year at his suggestion. More recent captchas no longer include additional horizontal lines intended as extra 'noise'. Instead, Google has increased the extent to which it stretches and deforms captchas – this hinders segmentation, required for achieving better OCR results. According to Wilkins, however, these distortions can probably be reversed.
In contrast to other captcha procedures, reCAPTCHA presents the user with two real words. The words are taken from Google projects for digitising books and old newspapers and represent cases where OCR has failed. In doing so Google kills two birds with one stone, in that it has a free captcha service and the assistance of millions of users in plugging gaps in scanned texts. But this begs the key question, 'how does reCAPTCHA know that the entered words are correct if Google's systems have failed to decipher them?' The answer is, that it doesn't. Only one of the two words is actually unknown – answers from other users have already been collected for the other. If the value for the known word matches the value given by other users, reCAPTCHA assumes that the user has also correctly recognised and entered the unknown word.
Despite the improvements, Wilkins claims that reCAPTCHA still has some weaknesses. It is based on existing English words, resulting in a significant reduction in entropy. Furthermore, Google itself only knows one of the two words displayed, and even permits some errors in entering this word. Wilkins states that he would need some time to carry out a new analysis, time which he says he does not at present have. He says he is surprised that his publication seems to have struck a chord, having, as he noted on Twitter, intended it only for a few friends.
One alternative to text-based captchas is motif-based captchas, such as Microsoft's Asirra, which requires users to highlight all the cats in a block.
(djwm)








![Kernel Log: Coming in 3.10 (Part 3) [--] Infrastructure](/imgs/43/1/0/4/2/6/7/2/comingin310_4_kicker-4977194bfb0de0d7.png)

![Kernel Log: Coming in 3.10 (Part 3) [--] Infrastructure](/imgs/43/1/0/4/2/3/2/3/comingin310_3_kicker-151cd7b9e9660f05.png)








