Hortonworks unveils Stinger Initiative
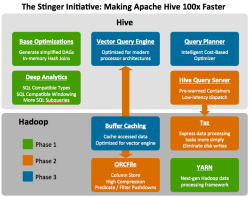
![]() The Stinger Roadmap - phase by phase
The Stinger Roadmap - phase by phase
Hortonworks' Alan Gates has announced the Stinger Initiative, a four point plan for making Apache Hive 100 times faster. With other Hadoop distributors already having taken steps to speed up processing of large data volumes (e.g. MapR's Drill), Hortonworks prefers to rely on existing tools and input from Hadoop's large community.
Hadoop is a framework for distributed applications written in Java and is one of the major projects of the Apache Foundation. Gates notes that Hadoop was designed for batch processing and is very effective at that, but modern use cases also include more realtime or interactive demands. Hive is a subproject of Hadoop which adds the SQL-like query language HiveQL and indexing to the project and Gates says the initiative aims to "answer human-time use cases such as big data exploration, visualisation and parameterized reports" within 5 to 30 seconds without needing another tool.
According to the plan now unveiled, the first element will involve better tailoring of Hive to the type of queries users want to perform on Hadoop, specifically decision support queryies. This includes introducing analytics features such as the OVER clause, supporting subqueries in WHERE and aligning Hive's type system to be more in line with standard SQL.The analytic functions are already being worked on within the Hive project as HIVE-896.
The second element involves revamping Hive's query execution plans where Hortonworks has already seen a drop of 90% in query time. They are also considering making changes inside Hive's execution engine to increase the number of records per second a Hive task can process.
The final two elements are a new column-based file format (ORCFile), which is said to be a "more modern, efficient, and high performing way to store Hive data", and new runtime framework Tez. The latter aims to reduce constraints imposed by using MapReduce, in part by eliminating unnecessary tasks and synchronisation barriers and reducing the number of reads and writes to HDFS.
An initial preview of the planned changes should be available in time for the Hadoop Summit in March 2013. Staff from companies such as SAP and Facebook have already started work on some of the points outlined – the results can be viewed in the Hive issue tracker.
(djwm)
![Kernel Log: Coming in 3.10 (Part 3) [--] Infrastructure](/imgs/43/1/0/4/2/6/7/2/comingin310_4_kicker-4977194bfb0de0d7.png)

![Kernel Log: Coming in 3.10 (Part 3) [--] Infrastructure](/imgs/43/1/0/4/2/3/2/3/comingin310_3_kicker-151cd7b9e9660f05.png)
















