
The fork/join framework in Java 7
by Patrick Peschlow
When should the new ForkJoinPool be preferred to the old ThreadPoolExecutor and when is it better to let it be? This article explores the major new features in the Java 7 fork/join framework and compares its performance in two practical applications.
A major new feature in Java 5 was the ExecutorService, an abstraction for executing tasks asynchronously. The ThreadPoolExecutor implements this concept using an internally administered thread pool, the worker threads of which work their way through the tasks arising. The ThreadPoolExecutor has a central inbound queue for new tasks (Runnables or Callables), which is shared by all worker threads.
One disadvantage of the ThreadPoolExecutor is that a competition situation can arise when threads try to access the shared inbound queue and the synchronisation overhead can waste valuable task processing time. There is also no support for having multiple threads collaborate to compute tasks.
Since Java 7, an alternative implementation of the ExecutorService has been available in the form of the ForkJoinPool. This uses additional structures to compensate for the disadvantages of the ThreadPoolExecutor and potentially permits more efficient task processing. The underlying concept, the fork/join framework, was first presented� ![]() by Doug Lea in 2000 and has since undergone further refinement and improvement.
by Doug Lea in 2000 and has since undergone further refinement and improvement.
There is fairly widespread uncertainty as to when the ForkJoinPool should be used in practice. This is partly because a lot of tutorials focus on "sandbox examples", which can create the impression that the ForkJoinPool is only suitable for artificial problems or very specific applications. Further confusion can be sown when the ForkJoinPool fails to deliver improved performance in promising scenarios or even delivers poorer performance than the ThreadPoolExecutor.
This article aims to shine a light into the darkness and, using real-life examples, create a better understanding of the types of scenarios that ForkJoinPool is suitable for and why.
How it works and structure
Just like the ThreadPoolExecutor, the ForkJoinPool uses a central inbound queue and an internal thread pool. With the ForkJoinPool, however, each worker thread has its own task queue, to which it can add new tasks (see figure 1). As long as its own task queue still contains tasks, each thread sticks to processing only these tasks. When their task queues are empty, threads employ a work-stealing algorithm, in that they search through task queues belonging to other worker threads for available tasks and process them if found. If they fail to find one, they access the shared inbound queue.
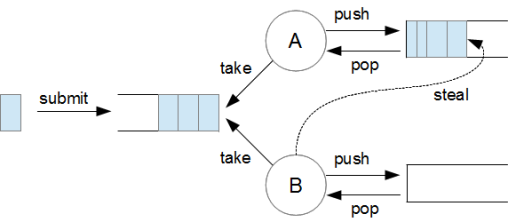
![]() A ForkJoinPool with two worker threads, A and B. In addition to the inbound queue, each thread also has its own internal task queue. Each thread starts by processing its own queue, before moving on to other queues (figure 1).
A ForkJoinPool with two worker threads, A and B. In addition to the inbound queue, each thread also has its own internal task queue. Each thread starts by processing its own queue, before moving on to other queues (figure 1).
This procedure has two potential benefits. Firstly, where possible, each thread works only on its own queue for an extended period of time without having to interact with other threads. Secondly, threads have the ability to take work off each other.
To minimise overhead from the additional queues and from work stealing, the ForkJoinPool implementation incorporates major performance enhancements. Two factors are worth stressing:
- The worker thread task queues use a deque (double ended queue) data structure which supports the efficient addition and removal of elements at both ends. The worker thread works at only one end of the deque, as with a stack. It both places new tasks on (pushes) and fetches tasks for processing from (pops) the top of the stack. When stealing work, the other threads, by contrast, always access the other end of the deque. Consequently, threads usually only face competition when they attempt to steal work from the same queue – and even if that happens, the thread "owning" the queue is rarely affected by that competition.
- A potential problem is that, should a thread attempting to steal work fail to find an available task, it could burn CPU time by continuously trawling through the same empty queues. To prevent this, "unemployed" worker threads switch into a rest state in accordance with a fixed set of rules. The framework then addresses them specifically when tasks become available once more.
Fork and join
It is important to note that local task queues and work stealing are only utilised (and therefore only produce benefits) when worker threads actually schedule new tasks in their own queues. If this doesn't occur, the ForkJoinPool is just a ThreadPoolExecutor with an extra overhead.
The ForkJoinPool therefore provides an interface to allow tasks to explicitly schedule new tasks during execution. Rather than Runnables or Callables, ForkJoinPools work on what are known as ForkJoinTasks. During its execution, a ForkJoinTask possesses a context within which newly created ForkJoinTasks are automatically added to the local task queue (forked). If the original task requires the results of the forked tasks, it can wait for them and add them to the overall result (join). To simplify the use of fork and join, there are two specific implementations of the ForkJoinTask: the RecursiveTask returns a result, the RecursiveAction does not.
Appropriate scenarios for the ForkJoinPool
One scenario in which tasks schedule further tasks is based on the principle of splitting – if the amount of computing required for a task is very large, it can be recursively split into several small subtasks. Work stealing means that other threads will also contribute to processing these tasks (and will split their own subtasks further where possible). Only if a subtask is deemed to be small enough (according to a defined set of rules), and splitting it further is not worthwhile, will it be computed directly. What makes this approach particularly tempting is that very large subtasks that other threads can then immediately steal are created at the start of the process of recursively splitting tasks. This favours even load balancing between threads.
In another, often underestimated, scenario, tasks schedule further tasks without any splitting. A task then represents a self-contained action, but nonetheless triggers follow-up actions represented by additional tasks. In principle this can be used to model any type of event-driven process. In the extreme case of such a scenario, each worker thread could continually provide itself with further tasks. All threads would be busy but there would still be no competition situations.
Below, we look at how the ForkJoinPool compares to the ThreadPoolExecutor in the above two scenarios using one real-world example for each. The full source code for the examples is available on GitHub.








![Kernel Log: Coming in 3.10 (Part 3) [--] Infrastructure](/imgs/43/1/0/4/2/6/7/2/comingin310_4_kicker-4977194bfb0de0d7.png)

![Kernel Log: Coming in 3.10 (Part 3) [--] Infrastructure](/imgs/43/1/0/4/2/3/2/3/comingin310_3_kicker-151cd7b9e9660f05.png)








